
Introduction
The AI Dino Agent is a computer program that plays the Chrome Dino game without any human aid. The goal of the agent is to primarily attain a good high score and also to play the game in a way that is indistinguishable from a human.
Usage
This project has only been tested with Windows. Therefore, ensure that you clone the repository in a Windows environment.
Setup
- Clone the repository
- Ensure Python version >= 3.6.8
- Install the relevant pip packages.
pip install -r requirements.txt - Download the binary_models (banana_v1.pt) from here and save it under /binary_models folder.
- Run the Game
python dino_agent.py
The agent in progress:
Tech Stack
This project was built using Python, PyTorch and Selenium.
Click here to view the code repository.
Approach
The game is simple in the sense that there are only two controls for the player - a jump command and a duck command. The Dino character jumps over obstacles and ducks away from flying creatures - birds etc based on the respective commands. Doing so for a considerable amount of time builds the score.
Current Methods vs Our Method
There have been multiple attempts in solving the Dino game problem. These attempts revolve around the use of Reinforcement Learning and Q-Learning, thereby bypassing the need for a labelled dataset. In place of a dataset, these techniques allow the agent to build proficiency by employing the use of repeated automated simulations.

However, in this project, we take a different approach - we convert the problem into an image classification task. This way, the challenge in turn becomes building a classifier that, given a particular game state, classifies between three different moves - jump, duck or inaction. A game state here is represented by a fullscreen screenshot of the game in progress.
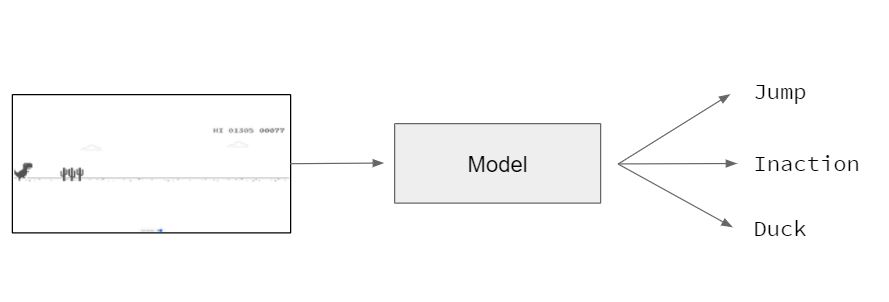
Simplifying the Problem
At this point, it was difficult to determine if converting it to a classification task would be sufficient for the agent to play somewhat well.
The game naturally tends to increase the speed of the agent as the score increases. Since a static screenshot does not convey speed, we decided to do away with the speed aspect of the game for the time being. This way, the neural network would only learn to jump/duck for a single speed setting; constant speed of 6.
Architectures
Four category of Neural Networks (NN) were explored to build a classifier for this task - Multi-Layer Perceptron (MLP), Convolutional Neural Network (CNN), Recurrent Neural Network (RNN) and Attention Neural Network (ANN). These categories were explored by first building the simplest architecture that was functional, and then subsequently increasing the number of parameters. These models were then trained and tested on the collected data - images - before packaged in a Selenium-based script to automate real-time game play.
Model Evaluation
Two evaluation techniques were considered for this task. Having a labelled dataset that we built from scratch allowed us to employ the simplest way to evaluate model accuracy - by simply counting the number of wrong predictions over all test data. This gave an accuracy score for each model. Therefore, this was the main metric used to quantify the performance of a model.
The second approach, which we later developed, was to use the Selenium-based script to automate the game in real time. This allowed us to calculate the average high score of a set of games for each model, which served as a performance metric.
We mostly ended up using the first technique as it gave a quicker and efficient way of measuring performance. In contrast, the second technique needed constant attention as a single game sometimes took > 5 minutes to complete.
Final Solution
Among all the architectures we experimented with, we observed the best results from the CNN category. We explored a few configurations with varying parameters and settled upon a LeNet5 based architecture (Banana) that gave the following performance:
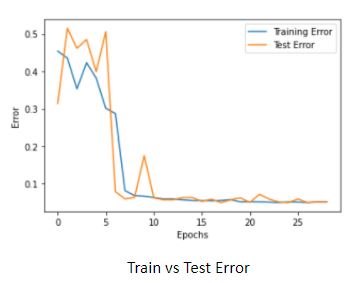
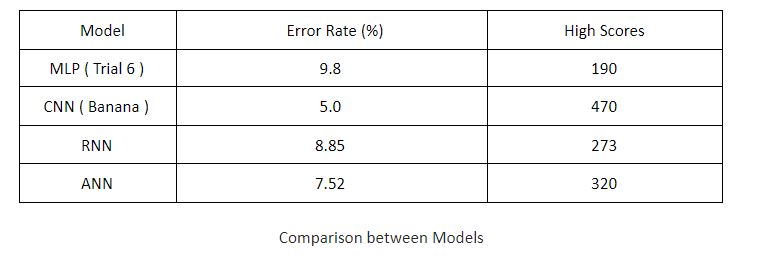
Based on the results from evaluating the test set and also evaluating using live games, we came to the conclusion that it was possible to solve the problem of building an AI Dino Agent - albeit on a modified game with simplified rules - by converting it into a classification problem.
Thoughts
This project was done with 2 other students for a Master’s level Deep Learning course (CS5242). The module coordinators were pretty clear about making sure that this was not a project that involved hours of training using high-calibre GPUs. Instead, it was about writing different architectures from scratch and experimenting with different parameters for a given problem that required learning.
The project was open-ended, and I liked that. We wanted to try building an agent that did not use reinforcement learning but simple classification, and I believe we managed to do that.
Interesting stuff.